Published: |
I vibe coded Kahoot
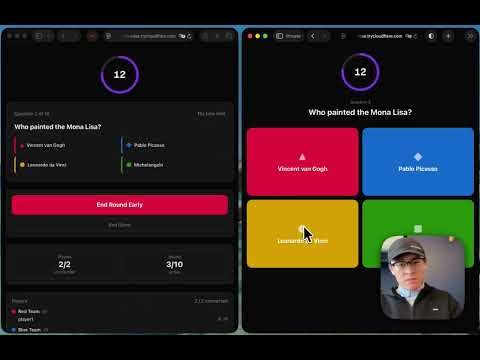
Last week was Chinese New Year 🐴, and I had the idea of hosting a trivia game with my colleagues. Instead of using an app like Kahoot, I decided to vibe code a trivia app myself and test the limits of the latest models.
AI assisted coding was not new to me, but launching a greenfield project purely with AI from start to finish, with specific requirements, a deadline, and to be tested with real users? That is new for me.
tl;dr: after three hours and estimated $10 spent on Claude Opus 4.6, the trivia app is complete and it works.
Source code: https://github.com/bodadotsh/vibe-coded-trivia-app
First of all, this app wasn’t made with a simple prompt “make me a trivia app” and that’s it. This blog post is to document the planning, process and decisions in between that I believe made a difference.
Maybe in 6 months, the AI landscape would’ve changed so much and this blog post will be out-of-date and feels like a relic. In that case, I can come back to this post and laugh about how naive everything was back then.
Initial Planning
Right from the beginning, I knew that reducing complexity or not over-complex matters will be a key factor. With that in mind, here are few technical decisions I made early on to reduce complexity (for the AI at least):
- I don’t plan to deploy this anywhere. The users are my colleagues for one temporary session, a solution like ngrok or Cloudflare Tunnel would be enough.
- Give AI an established tech stack to work with. It is known that AI models are well trained on certain stack than the others. So I picked React, Next.js, Tailwind CSS and Node.js.
- Initial planned database and real-time communication solution was local JSON files and SSE (server side events). This felt simple enough for the MVP but it didn’t work out, so I switched to Supabase later on.
Initial Bootstrap
I like to spend the time to bootstrap the codebase myself. For the following reasons:
- Setup the foundational tools you want to use. For example,
pnpmovernpm,miseover other version managers etc. - The models are trained on historical data, and from my experience, they are more likely to install out-of-date library versions than not.
- This step is where you can setup AI harness techniques like
AGENT.mdor skills. - Linting tools like ESLint or Biome is critical. Agents will run linting between tasks and spot mistakes early.
Here’s what I did to bootstrap this project:
- Ran
pnpm dlx create-next-app@latestand chose the options myself. - Use
mise.tomlto ensure the correct tool versions are installed. - Added
AGENT.mdand few skills. - Added Biome for linting and formatting (also
.vscode/settings.jsonetc).
Initial Prompt
Personally, I switch between models for different tasks. Currently, I use Gemini 3 Pro as my reasoning model, I typically give it a detailed problem and ask Gemini to break it down or refine it. Then use Claude models for practical coding tasks.
I gave Gemini my list of requirements for the trivia app and ask it to refine it into a prompt template for Claude. (I couldn’t find my initial initial prompt where I described the entire flow of the app, it was like a typical game of Kahoot, with the limitations and expectations I mentioned above.)
Here’s the full initial prompt for Claude Opus 4.6:
Build a real-time, multiplayer trivia game web application (similar to Kahoot!) with a Host Dashboard and an Audience Player Interface.The app should support live game sessions where a host controls the flow and audiences compete individually and as teams.Tech Stack: Next.js v16 with React.js and TypeScript, Tailwind CSS, Node.js for backend.Database and Deployment: storing everything in a local JSON file (can be managed with npm package lowdb), this app will not be deployed anywhere,we are only exposing this app through CloudFlare tunnel to selected audience, and no external database solution is needed.
User Roles:1. Host- Creates a new game session and receives a unique Game Code- Sets a game password that audiences must enter to join- Create teams as audiences must select one to play the game- Each team have a name and a colour- Import trivia questions (from a local json file) before the game, each with:- Question text (supports text only)- 4 multiple-choice options- One correct answer- A configurable time limit per round (e.g. 10s, 20s, 30s, 60s)
Controls the game flow:- Start game — new players can still join even midway through the game- Next round — reveals the next question to all audiences- End round — manually ends the round early (or it auto-ends when the timer expires)- Show results — displays the correct answer and live leaderboard after each round- End game — displays the final leaderboard and closes the session
Views a real-time dashboard showing:- Number of connected players and teams- Live response count as audiences submit answers- Distribution of answers per option (bar chart) after each round
2. Audience (Player)- Joins a game session by entering: the Game Code, the game password, a display name (validated for uniqueness within the session)- Join a team from a list in the lobby- Sees the question and options when the host starts a round- Submits an answer once per round (no changing after submission)- Sees their own result (correct/incorrect) and current rank after each round- Sees the live leaderboard (individual + team) between rounds
Scoring System- Base score per correct answer: 1 point- Time bonus: The faster the correct answer, the higher the score. Use a linear decay formula:[\text{Score} = \text{Base} \times \left(1 - \frac{t_{\text{taken}}}{t_{\text{limit}}}\right)]where (t_{\text{taken}}) is time to answer and (t_{\text{limit}}) is the round's time limit.- Incorrect or no answer: 0 points- Team score: Sum of all individual scores of team members
Leaderboards- Individual Leaderboard: Ranked by total cumulative score- Team Leaderboard: Ranked by sum of all team members' scores- Both leaderboards update in real-time after each round and display rising/falling indicators
Security Requirements- Game password: Required to join; hashed server-side, never exposed to the client
Answer protection:- Correct answers must never be sent to the client before the round ends- The server validates all answers server-side; the client only sends the selected option ID- API responses during an active round must not include correct answer data- After the round ends, the server broadcasts the correct answer to all clients simultaneously- Input sanitisation: Sanitise all user inputs (display names, team names) to prevent XSS
Key events:- `game:join`, Client → Server, Player requests to join with code + password + name + team- `game:start`, Host → Server → All, Host starts the game- `round:start`: Server → All, Broadcasts question + options + timer (no correct answer)- `round:answer`, Client → Server, Player submits selected option ID- `round:end` , Server → All, Timer expired or host ended; broadcasts correct answer + scores- `leaderboard:update` , Server → All, Sends updated individual + team rankings- `game:end` , Server → All, Final leaderboard + session summary
UI/UX Requirements- Responsive design: Must work on mobile, tablet, and desktop- Lobby screen: Shows connected players, their teams, and a "Waiting for host…" state- Question screen (audience): Large, tappable option buttons with colour coding, countdown timer- Results screen: Animated correct/incorrect feedback, +score indicator, rank position- Leaderboard screen: Top 5 highlighted with podium-style display; full scrollable list below- Host dashboard: Split view — question preview on one side, live stats on the otherDespite the popularity of Claude Code, I still use Cursor. I almost always default to “Plan Mode”, and tell the AI to ask questions back for clarification. That is critical in further redefining requirements and constraints for the AI.
Pivot
The initial prompt on Opus 4.6 created ~35 files and ~6000 LOC. The UI looked good, but did it work? No.
Long story short, the app had issues with our Node.js backend, SSE, and Cloudflare Tunnels. I could switch SSE to WebSocket
and try socket.io, but given I’ve been building projects with Supabase, and I know the Supabase Realtime feature would be great
for this, I went back to “Plan Mode” and instructed the agent to switch the backend to Supabase.
This took few more iterations. And this is another example of the “developer” or the “agent conductor” needs some level of understanding of the tools or technologies they plan to use.
In my further prompts and plans, I told the agent how I want to setup PostgreSQL/Supabase, disable RLS, use declarative schemas, keep migrations simple, use raw SQL, use anonymous sign-ins, and enable real-time, etc.
If the “agent conductor” did not have knowledge of these details, they may increase the complexity, add more bugs/tech debts, and eventually deliver a sub-par product (slop).
I could’ve adopted a database ORM, like Drizzle or Prisma (as they are often the standards in this type of stack), but I knew they would add another layer of complexity, therefore I intentionally told the agents to avoid them.
Another example, Supabase announced their new types of API keys (Publishable and secret keys, to replace the previous anon and service_role)
in June 20251. But the Opus 4.6 (released in February 2026) still outputted old API key types.
Outcome
As I demonstrated earlier, the vibe-coded trivia app worked. I used it for a company brownbag, ~30 people used it in real-time to guess various trivia questions about CNY. We had a leaderboard at the end, I gave winners their prizes, people had fun, the app served its purpose.
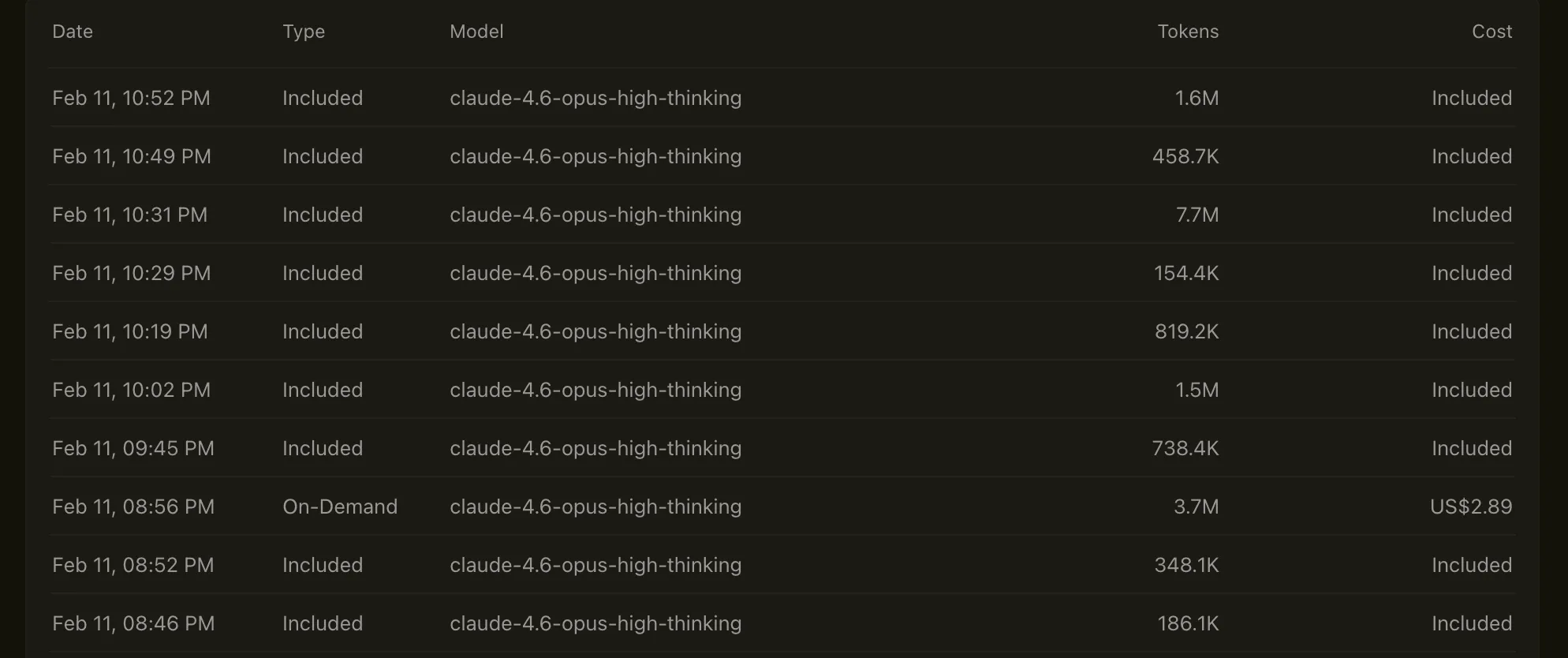
Total ~17M tokens were used, cost around ~$10, and approximately 20 kWh (a dishwasher running approximately 18 full loads) were consumed2
Closing Notes
It is becoming clearer that we need to adopt AI to our daily workflows. The velocity and productivity gains are undoubtedly more efficient than humans (at least in the short term). But the downsides of going full vibes ✨ are also more obvious to me now.
The longer I vibe code, the less I know about the codebase.
This was my first retrospective at the end of the vibe code session. I only knew about the explicit requirements and constraints that I told the agents in the prompts, but what about the smaller details and any assumptions the AI made between each tasks? No idea. In a world where even a semicolon matters, this is a big problem.
Not to say my own code won’t introduce these small ambiguities over time, but with AI, they are introduced faster to the codebase, and they were never even registered on my radar.
Also, if we have to pick a “AI-friendly” stack as they are mostly well trained on. Does that mean everyone will starting to pick similar stacks? Then publish these code as open source, and it will get trained onto newer models, and the cycle repeats? Is this the plateau of innovation?
Security.
Is this vibe-coded trivia app ready for production? Absolutely Not.
Why? Because I never audited it for security vulnerabilities. And I never even bothered to read the code. The entire codebase is a “black box”. Anything bugs, vulnerabilities, or any other issues could be in between these lines of code.
If someone hijacked a LLM model, and the LLM model injected malicious code into people’s codebase. This would have a catastrophic impact as if someone hijacked the Linux kernel.
Even when security platforms are offering “AI-powered” auditing services, you really hope it is not AI reviewing AI’s work…
I’m not 100% sure on this, but something tells me the security industry will see a boom in the next few years.
AI are not silver bullets. They are another level of abstraction.
It is true, as a web developer today, I never needed to learn about machine code, compilers, or how my React component turns into x86 instructions.
May the next generation of web developers never need to learn what a React useEffect hook is.
The difference is, the work previously done are deterministic.
same code -> deterministic system -> same outcomeToday, the same prompt to the AI will output different code every time. But the code still gets executed deterministically, resulting in a different outcome.
same prompt -> probabilistic system -> different outcomeThe AI’s work is probabilistic.
The developers of today need to manage and adapt to this new layer of abstraction in the systems we are building:
- prompting / code reviews / systems (✨ new baseline ✨)- languages / libraries / frameworks (2000s/2010s)- compilers / interpreters (80s/90s)- memory management / machine code (60s/70s)- hardwares (40s/50s)LLM models are like “car models”. People will shop around and look at review and specifications before making a decision. They will trust the brand of the model, the reputation of the company, and the price. And care less about the exact internal implementations.
The baseline trust factor moved from what code the developer writes, to how good the developer manages the system.
By “hiring” agents, you may increase the productivity by 100x, but you are no longer the doer, but the manager ensuring alignment and quality. Each time we review the agent’s work, we are “having a meeting” with the agent. The true effectiveness of a “good meeting” is an art on its own.
Looking ahead.
The conversations around AI right now are scattered, confusing and overwhelming. I am just as clueless as everyone else is. But I believe we are in another round of technological evolution, and it’s good to look at previous iterations to understand the current state and what we can expect in the future.
I saw this YouTube video about “American Dinners” recently. Back in the beginning of the 20th century, you could just buy a converted rail car, cook breakfast, and make a living out of it. Eventually, technology advanced, efficiency, profitability and maximum offerings became the goal. As a result, less and less individual entrepreneurs were able to compete with the large corporations. Today, the market is dominated by “convenience, cheap and fast”. Small entrepreneurs can only survive by moving toward specialisation and experience (things that a massive chain cannot easily replicate).

Sorry, was I talking about food or AI?